如果程式都必須以機械語言撰寫,那麼現在複雜的程式系統發展,如作業系統、網路軟體和市面上各種應用軟體都不可能實現,因為以機器語言來署理這些複雜的程式細節同時又要組織複雜的系統是非常困難的,因此許多程式語言的誕生讓演算法的表達式不僅可以讓人容易閱讀也可以輕易地轉換成機器語言指令,本章將探討計算機科學領域中關於設計與實作這些程式語言的相關議題。

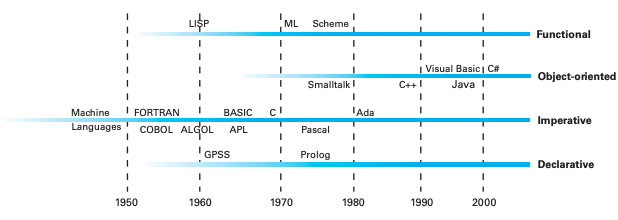
首先先介紹程式語言發整的一些過往與歷史。
以機器語言撰寫程式碼是一件非常繁瑣的工作且很容易發生錯誤,以致於需要找出並更正這些錯誤,這個程序就是俗稱的除錯 (debugging)。
在 1940 年代研究者發展了標記法用來簡化程式設計的流程,讓指令可以以通俗的名稱表示,常使用的描述性名稱 Price, ShippingCharge, TotalCost 通常稱為程式變數或識別符號 (identifier),而有了這些通俗的形式後便發展出了組譯器 (assembler) 它可以將通俗的表示法轉換成機械語言指令,而這種通俗表達程式的方式稱為組合語言 (assembly language),他被認為是第二代程式語言,第一在則是機器語言。
雖然使用組合語言可以比機械語言開發來的簡單,但還是需要程式設計師被迫以機器語言的角度思考,後來的設計者覺得最終產品會使用到的基本原是不需要在設計產品的階段就使用,設計過程應該使用更高級的原式,一但這些高級的原式設計完成後就能轉以為較低等級的語言或是概念,於是第三代程式語言就誕生了,他使用更高階的原式且與機械無關 (machime independent) 亦即他們不依賴特定機器架構。
要發展好這些高階語言就需要一種稱為轉譯器 (translator) 的程式將高階原式轉換成機器語言程式,他與第二代語言的組譯器很像不同的是轉譯器經常需要將數個機器指令編譯成段序列以還原單一高階原式所要求的操作,因此這些轉譯器經常被稱為編譯器 (compiler)。
有一種編譯器稱為直譯器 (interpreter) 是另一種實作第三代語言的方法,與轉譯器很相似但直譯器是在程式執行的時候進行轉譯,並不會另外與轉譯的結果一樣儲存起來以便日後使用,與其產生一份機械語言版本以供日後執行,直譯器可以讓高階程式直接執行。
程式語言會隨著不同的程式設計方法 (programming paradigm) 問世而有不同的發展路徑,比較常見的程式語言發展路徑分別為函數式, 物件導向式, 命令式, 宣告式等等。
也稱為程序式程式法 (procedural paradiam),代表傳統程式設計的方法,顧名思義命令式程式法是發展一系列的命令,用來處理資料以產生期望的結果,所以命令式程式法的程式設計過程是找出能解題的演算法,並將該演算法轉換為一系列的命令陳述。
宣告式程式法 是要求程式設計師在程式中描述需要解決的問題而非演算法,準確來說宣告式程式法使用預先建置好的通用解題演算法來解決程式設計師所描述的問題,因此程式設計師的任務就是精準的描述問題而不需要描述解決此問題的演算法。
程式被視為能接受輸入並產生一個實體,數學家稱這樣的實體為函數 (function),在此法下程式是藉由連結數個預先定義好的程式單元(預先定義好的函數)所構成,每個城市單元的輸出可作為其他城程式單元的輸入,簡而言之函數式程式法的程式開發過程就是以簡地的函數構建出複雜的函數,某種意義上來說函數式程式就好比一群協調一致的工廠,每間工廠只負責生產其他工廠所預定的產品,生產出的產品會立即送往需要的工廠,不需要中途儲存的倉庫。
物件導向式程式法與之相關聯的程式設計稱為物件導向程式設計 (object-oriented programming, OOP),這種程式法一個軟體系統被視為一群物件 (object)的組合,每個物件都能執行與自身相關的功能以及請求其他物件的功能,對於物件特性的描述稱為類別 (class),一但建立了類別就能在任何有需要的時候使用該類別建立帶有這些特性的物件,所以可以建立數個物件都基於相同類別,他們雖然是不同實體但卻有相同的特性,因為他們建立於同一個模板,由某個特定的類別所創立的物件,稱為該物件為此類別的實例 (instance)。
在本章中將探討命令式程式語言與物件導向程式語言的一些概念,選用了一些較為普遍或經典的程式語言進行介紹,C 語言是一種第三代程式語言,C++ 是延伸 C 語言而發展出來的物件導向程式語言,Java 和 C# 是衍伸於 C++ 的物件導向式程式語言。
一般來說程式包含著一群陳述,這些陳述分為三大類,宣告式陳述 (declarative statement) 定義了一些自定的名稱已變成是後續使用,命令式陳述 (imperative statement) 描述所有的演算法步驟,註解 (comment) 是以更通俗的方式說明程式中難以理解的細節以增加程式的可讀性。
高階程式語言使用描述性的名稱來代表資料於主記憶體中的位置而不是用數字來表示,這樣的名稱稱為變數 (variable)。
命令式程式語言有個分支稱為
腳本式程式語言 (scripting language)一般是用來執行一個管理層次的任務,並非用來發展複雜的程式,這種程式的表示型態稱為一個腳本 (srcipt)。
資料型別 (data type) 代表資料元素使用的編碼方式以及資料能夠進行什麼樣的運算,,比如整數 (integer) 資料型態可以處理整數類的資料,字串 (string) 則是處理文字類型的資料。
資料型別包含在程式語言的原式中,比如 int 代表整數型別,char 代表字元型別,這些資料型別稱為基本資料型別 (primitive data type)。
除了資料型別之外,有些變數也會連接到資料結構 (data structure),資料結構是資料的意向或資料排列的方式。
陣列 (array) 是一種常見的資料型態,是一組具有相同型別的元素所組成,一但陣列宣告後就可以在程式中以其名稱表示,或個別的陣列元素項目可以使用索引值 (indices) 來指定特定行列以做為識別。
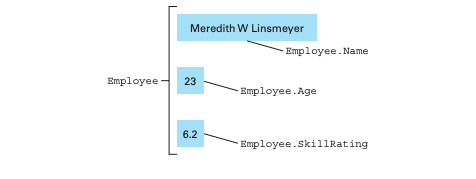
相較陣列的所有資料項目是同的類型,一種聚合類型 (aggregate type) 是一組具有不同型別的元素集合,他也被稱為 structure, record 或異質陣列 (heterogeneous array),在 C 語言中宣告如下:
struct {
char Name[25];
int Age;
float SkillRating;
} Employee;
在電腦的儲存空間中,資料結構的真實排列方式可能與意象的排列方式有很大的不同。
有時候程式會需要用到某個固定且預設好的數值,像這樣明確的數值在程式中稱為定數 (literal),在程式陳述式中使用定數
EffectiveAlt = Altimeter + 645;
其中 EffectiveAlt 與 Altimeter 是變數而 645 則是一個定數,而上面的式子也可以稱為一個運算式 (expression)。
不過如果是一個多人開發的大型專案的話,可能除了你之外其他所有人都不會知道 645 是什麼東西,為了解決這個問題程式語言允許使用否過名稱只定為不會變動的某數值,這種就稱為常數 (constant),比如
const int AirportAlt = 645;
這樣代表名稱 AirportAlt 是個具有固定數值的 645 的東西。
一但某個特殊名稱要被宣告在程式中使用時,就可以開始使用命令陳述來為這個變數指定一個值(精準點是說,指定給該變數所代表的記憶體位置一個值),這種基本的命令陳述稱為指定陳述 (assignment statement),指定陳述句的重心在等號的右半部。
控制陳述 (control statement) 可改變程式的執行順序,比如最受爭議的 goto 陳述,他可以讓程式的執行跳到任意指定位置。
無論一個程式被設計得多好多巧妙,當有人需要詳細研究這份程式時,一些附加的訊息會對這個研究的過程非常有幫助,因此程式設計師可以在程式中添加一些說明,稱為註解 (comment),這些註解會被解釋器所略過,因此以電腦的角度來說有沒有寫註解是完全不影響程式運行。
在前幾章中介紹了將大型程式分割為小單元的好處,在本章終將著重介紹函數的概念,函數是在命令式程式語言讓程式模組化的主要方式。
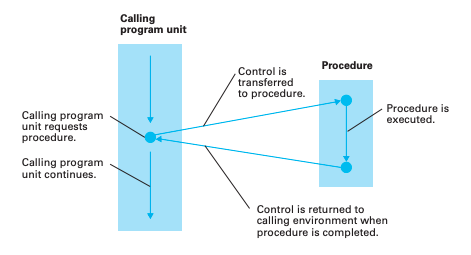
函數 (function) 是執行某個特定任務的一群指令,使用時控制權會轉移到函數上,等函數完成後再將控制權交回到原來的程式單元,轉移控制權給函數的過程稱為呼叫 (calling) 或調用 (invoking),而請求執行函數的程式單元稱為呼叫單元 (calling unit)。
函數通常是作為個別的程式單元,這個程式單元一開始的陳述稱為函數的標頭 (header) 亦即函數的名稱,而通常在函數內部所宣告的變數稱為區域變數 (local variable),意味著這個變數只能在這個函數內部使用,這樣可以避免函數外洩或函數名稱重複的問題,變數在程式中有效的使用範圍稱為範疇 (scope),有興趣的話可以看看我寫的 You Don't Know JavaScript [Scope & Closures] - What is Scope? 會提到一些關於 Scope 的內容。
通常函數會使用一般性方式轉寫,等到函數真正執行時才會比較具體,如果想要使用某個函數的話則需要將某變數指向函數指定的內容,這個指向函數內容的東西稱為參數 (parameter),更精確的說在函數中所使用的名稱為形式參數 (formal parameter) 而函數執行時指定給這些形式參數實際名稱的稱為實際參數 (actual parameter)。
實際參數與形式參數之間進行資料傳遞的任務在不同程式語言中有不同的方式,有些程式語言會複製一份實際參數給函數使用,使用這種方式的話函數中資料的任何異動都只會影響到這一份複製的內容,而呼叫單元的資料不會有改變,這種方式稱為傳值 (passed by value)。
不過如果當參數是一組大量資料時傳值參數的效率就會很不好,比較有效的方式是讓函數直接存取實際參數,讓呼叫單元告訴函數實際參數在主記憶體中的位置,這種方式稱為傳址 (passed vy reference),這種傳遞地址的方式由於是直接操作地址中的內容,所以在函式中的異動會隨之影響到呼叫單元的內容。
Passed by value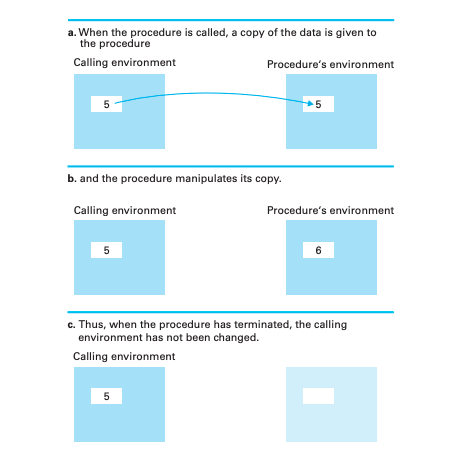
Passed by reference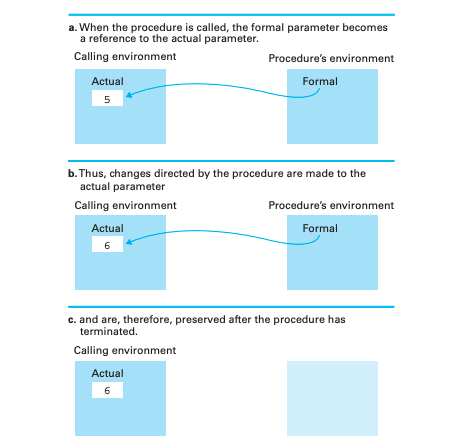
在某些情況下函數可以透過事件的發生來啟動,比如說在 GUI 中點擊某個按鈕時,函數不是透過其他程式單元的呼叫而是因為按鍵被點擊而啟動執行,函數經由事件的發生而啟動執行的軟體系統稱為事件驅動 (event-driven) 系統,簡而言之事件驅動軟體系統描述不同事件觸發時會發生的結果,當系統執行時函數是靜止的直到相對應的事件發生後函數才會啟動,函數啟動且執行完成後便會再次回到靜止狀態。
在本章中會探討高階程式語言所撰寫的程式被轉譯成機器可執行的形式過程
將某一種程式語言所撰寫的程式轉換為另一種語言的過程就稱為轉譯 (translation),原本的程式稱為原始程式 (source program) 而轉譯過的程式目的程式 (object program),轉譯過程包含三個步驟 - 詞法解析 (lexical analysis), 語法解析 (parsing) 與程式產生 (code generation),並由轉譯器裡面一個稱為詞法分析器 (lexical analyzer), 語法解析器 (parser) 與程式生產器 (code generator) 的元件負責執行。

詞法分析是便是原始程式中哪些字串代表單一實體或標記 (token),比如說 153 不能被轉譯為 1, 5 和 3 而應該要被解析為單一數值,因此詞法分析匯一個符號接著一個符號的讀取程式碼,辨識哪些符號構成一個標記並根據標記分類為數值,字詞或算術運算子等等,詞法分析器會對每個標記和他的分類進行編譯並交移給語法解析器,在這個過程中註解會全部被跳過。
語法解析器以語詞單元 (token) 來檢視程式而非個別符號,語法解析器將這些語詞單元組成陳述,早期的程式語言強調每一句程式碼的陳述必須在頁面上以特定的方式定位,這種程式語言稱為固定格式 (fixed-formal) 語言,現在許多程式都是自由格式 (free-formal)語言,亦即陳述的定位並不重要,因此可以使用縮排來幫助開發者很快的知道陳述的結構因此與其
if Cost < CashOnHand then pay with cash else use credit card
可以把它更改為較好看懂的形式
if Cost < CashOnHand
then pay with cash
else use credit card
大多數自由格式語言使用分號來標示陳述的結束,以及使用關鍵字 (key word) 比如 if else, then 等等來標示個別陳述的起頭,這些關鍵字通常是保留字 (reserved word),代表他們不能被開發者作為其他變數使用。
解析過程是基於程式語言的語法規則,這些規則整體稱為文法 (grammar),描述這些規則的方式之一是使用語法圖 (syntax diagram),這是一種以圖形表示程式語言的文法結構。

上面的語法圖說明了 python 的 if-else 陳述,要注意的是在這個語法圖中實際出現的專有名詞是以橢圓表示,而需要進一部描述的地方則使用矩形比如布林運式或縮排陳述句,這些需要進一部描述的地方稱為非終端點 (nonterminal),而已橢圓表示的稱為終端點 (terminal),而特殊字串對應到語法圖的方法可以使用解析樹 (parse tree) 來表達。
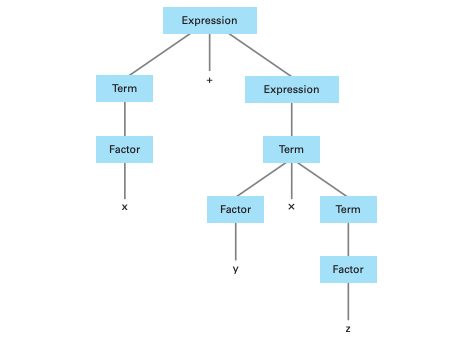
解析程式的過程基本上就是建構城市解析樹的過程,事實上解析樹代表程式文法組成的解析結果,因此描述程式文法結構的語法規則不能允許同一個字串有兩種不同的解析樹因為會造成語法解析器的混淆。
轉譯過程的最後一個步驟就是程式產生 (code generation),這是建構出機械語言指令以實作解析器辨識的陳述程序,在這個程序中有一個重要的任務那就是產生有效率的機器語言指令,比如
x = y + z;
w = x + z;
如果這兩個陳述個別轉譯成機器語言指令,在執行加法前每陳述都需要將資料從主記憶體傳送到 CPU 中,但如果第一個陳述已經執行完畢並把 x 與 z 的內容存於 CPU 的通用暫存器中,這樣當要進行第二次加法運算前就可以將資料從記憶體中載入,這樣洞悉陳述以實作機器指令的方式稱為程式碼最佳化 (code optimization)。
最後要注意的是詞法解析 (lexical analysis), 語法解析 (parsing) 與程式產生 (code generation) 並沒有固定的步驟也沒有強制的順序,在程式轉譯的過程中這些動作會互相交織再一起。
讓多個程式同時執行就稱為平行化處理 (parallel processing) 或並行處理 (concurrent processing),真正的平行話處例需要多個 CPU 核心,每個核心都用來執行一個程式,不過如果只有一個 CPU 的話就會像前面提到的利用處理器分時的方式產生平行話處理的錯覺。
每種程式語言從自身角度詮釋平行化處理的方式造成不同的用語,比如 Ada 同時執行多個動作需要多個 task,在 Java 中啟動多個程式稱為 thread,不管是哪一種其結果類似於多工作業系統控制的程序,產生多個工作同時執行的效果,本章會採用 Java 的用語以 thread 來介紹。
傳通呼叫函數執行時呼叫程式單元只有在函數終止後才能繼續動作,而在平行化處理下呼叫函數執行後呼叫單元可以同時繼續執行,
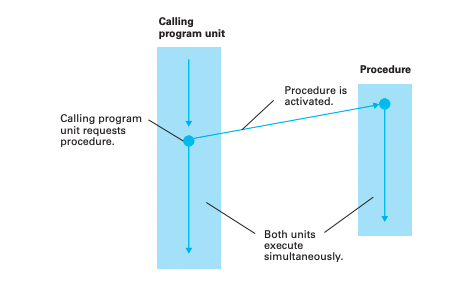
平行化處理中比較複雜的問題是要處理 thread 之間的溝通,這種溝通的需求一直都是計算機科學研究的主題之一,有一種方式是每次只允許一個 thread 存取的資料被稱為互斥存取,而實作互斥存取的方式之一是寫一個包含 thread 描述的程式元件,當有一個 thread 在存取資料時他會阻擋其他 thread 進行資料存取直到該 thread 結束存取任務,不過在過往的經驗中這種方式會造成控制互斥的程式碼遍佈程式中,一個不小心就會讓整個系統垮掉基於這個原因許多人認為比較好的方式是共享資料的情況下可以控制本身的存取,簡而言之就是與其仰賴 thread 來避免資料的多重存取倒不如讓資料自己控制,因此存去控制就能集中在程式的單一位置而不會擴散到整個程式中,能夠自我控制存取的資料稱為監控器 (monitor)。
 Fandix
Fandix
